It seems clear that bugs in software systems must be found, and that good tools are needed to assist the programmer in this complicated task. As most of you might know, there is a very capable debugger available as free software from (who else?) the GNU project. Since the GNU people are responsible for the most important compiler under linux, the gnu c compiler, both programs form a bodacious and capital team when it comes to kill nasty bugs in your programs. Those of you who have already used the debugger know its spartan interface: It's not bad, but not too good either. Even if one is a friend of the command line and text-based utilities (as the author certainly is), using this form of debugger interaction is not always hilarious and can be a quite poignant exercise, especially when larger systems with complex data structures are debugged. The text interface may be well suited for single-stepping through programs, checking simple values or testing certain conditions, but it is certainly not the optimal choice for modern, effective and easy-to-do debugging of structures deeply connected with each other. Other interfaces (like the emacs gud-mode or the new tui interface for gdb) offer slightly more comfort, but are not ideal as well.
We need a graphical interface therefore, and again the GNU project offers a very good possibility: DDD, the data display debugger. DDD is a graphical interface written by Andreas Zeller and Dorothea Luetkenhaus (and the help of many other programmers from the free software community) and made into a GNU program some time ago (although it was GPLed already before that). If debugging weren't such a sometimes very hard job, we would nearly be tempted to say that debugging with ddd is mere fun.
What does ddd offer compared to the pure gdb interface or to other debugger front ends like the emacs gud-mode? The main point is not just DDD's normal debugging functions (e.g., stepping through your source file line by line, setting breakpoints and watchpoints, changing the values of program variables), which are supported by ddd (in a very convenient and much simpler way compared to the traditional gdb interface), but that DDD can also display data structures graphically. What does this mean? Consider a linked list in C, as we will use it in one of our later examples. The data structure basically consists of several data fields together with one or more pointer fields to other structures of the same type, that together form an interconnected network. The network is made up of the values of the pointer variables. It could in principal by reconstructed by their hexadecimal contents, giving the memory location of the previous or following elements, but this is neither a very convenient nor comfortable task. It is very difficult to produce a concise overview about the situation this way, and even if the programmer succeeds in that laborious task, there is a major drawback: Since memory locations change in the next program run (or when a different input dataset etc. is used), the work is quickly rendered useless. DDD overcomes this limitation by automatically creating diagrams from the memory contents, allowing a simple and appealing visual view to complex structures.
But the ability to draw program structures graphically is not the only enhancement offered by ddd compared to classical dialog-based debugging methods:
Let's see how all these things look in practice by debugging a simple example program.
The standard option to include debugging information in a program is to use the switch -g when calling gcc:
@jupiter wolfgang]$ gcc -g fac.c -o fac
This will create a binary file fac which is bigger in size than the normal executable. Obviously, this is not a big surprise: Since additional data (like assignments between blocks of machine instructions and line numbers in the source code etc.) are stored in the code now, the size must increase.
It is important to note that gcc offers a feature quite rare among competing compilers: Debugging information can be generated even if optimizations are turned on, e.g. gcc -g -O2 fac.c fac will work, producing a binary file that is optimized and contains debugging information. Although this can be quite handy in some cases, there are some well hidden trap doors behind this approach (like optimizing away several lines of code), so we won't cover these combinations here.
The source file for fac.c has the following contents:
#include<stdio.h>
int main() {
int count;
int fac;
for (count = 1; count < 10; count++) {
fac = faculty(count);
printf("count: %u, fac: %u\n", count, fac);
}
return 0;
}
int faculty(int num) {
if (num = 0) {
return 1;
}
else {
return num * faculty(num - 1);
}
}
As you can see, the program just performs some really simple calculations: We loop over a range of integer values from 1 to 9 and call a function to calculate the number's faculty in every loop step. It's perfectly clear that this could be done in a much more efficient way, but it serves as a good example for general debugging techniques. By the way: It will not run correctly, since it contains an error. You can check this by executing it in a normal shell, without an attached debugger (binaries with included debugging symbols run like normal programs, they are just a little bit slower): The only thing you get is a core dump that happens due to a segmentation fault. So let's put the program into the debugger and find out what's wrong!
@jupiter wolfgang]$ ddd&
at your prompt; the file name of the program that shall be debugged can be supplied as an optional argument. If ddd is not installed on your system, this can almost certainly be done using your favorite package management system (like apt-get, rpm etc.), since ddd binaries are supplied with all major distributions. In case there is no binary package for your system (or if you want to compile ddd from scratch for some reasons), get the source distribution from ftp.gnu.org (or preferably one of it's mirrors) and follow the instructions in the INSTALL file accompanying it.
If you did not supply the file name on the command line, you can select
it via the File->Open Program menu entry via a dialog box. ddd then
loads this program, parses the debugging symbols (or, to be precise:
lets the back-end debugger parse the symbols)
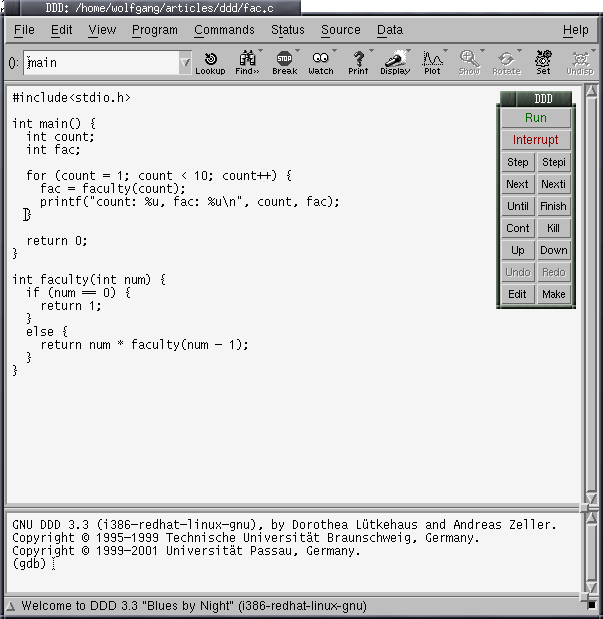
and loads the main source file afterwards. Your display should show
a window similar to figure 1.
The ``Command Tool''-Subwindow is very important for our later work. By
default, it is shown in the main window's right area, offering
several buttons to perform diverse actions with our
code (in case you should close the window incidentally, you can reopen
it either via F8 or the View->Command Window menu item).
Now we can get the ball rolling: Select ``run'' from the command tool, which will instruct the debugger to start the code. The program doesn't run very long, since our breakpoint is located at the very beginning of the file; we are now in a debugger interaction mode. The green arrow to the left of the source lines shows us the line that will be executed next in the source file.
There a two possibilities to step through a source code: While ``next'' takes you line by line, but omits procedure calls (and just presents you the result of the call), ``step'' will dig through the subroutine's code when it is called. As we want to see what's wrong in our program (since the error is a very common one, experienced programmers will have seen it already certainly), we decide to ``step'' through the program. Press the button, and you will find the green source line pointer right in the beginning of the faculty subroutine. This is what we intended, so you can press ``step'' another time, leading the green arrow directly into the else-branch of our conditional decision. This is all right again. What would we expect now? Since num had the value 1 when we entered the subroutine, it should be 0 when we enter the subroutine again recursively, resulting in an immediate return of the value 1, which should again result in returning 1*1=1 from our first call of faculty, leading us back to the main program. Let's check whether this is what actually happens by pressing ``step'' for another time: The green pointer moves again to the beginning of the function, but enters the else-branch again in the next step! Obviously, something went wrong: We need to check num's value.
There are several possibilities to show the value of simple variables
(e.g. variables of simple types like int, long, float etc.). The most
common one is to keep the mouse pointer over the variable in the source
window, waiting until a tooltip with its contents appears on the screen.
Alternative ways are to press the right mouse button right over the identifier
and select Print num from the popup menu or to mark the identifier
and select the Data->Print() menu entry. With the last two methods,
the value is displayed in the gdb output window in the lower region
of the main window.
Regardless of the method used, we receive 0 as num's value. Why has the second branch been taken, although num is 0? Using step for another time confirms your possible assumption about the error case: If we look at the value of num right at the beginning of the function, we see that it is -1, but in the next step (again the second branch of the if-conditional), it is 0 again: The error is a forgotten = in the if-clause, resulting in an assignment rather than a comparison! Although this is a very common error in C programs, it can cause considerable delay to the program's development if it is only well enough hidden. Since we won't receive any meaningful result from this incorrect program, we can kill it with the ``kill''-Button in the execution window.
Correct the error by exchanging the "=" with a "==", recompile the program (don't forget to include debugging symbols again!) and reload it into ddd via the "File"-menu. As you can see, out breakpoint is conserved, so we can start the program again from the very beginning. If we step through the faculty call now, everything works alright. The faculty function is completed, and the green source line pointer is now in the printf(...)-line. We need to be careful: If we select ``step'' for another time, ddd will try to step through the print call, which is not possible, since the function is taken from the standard C library which is normally not compiled with debugging symbols (although it's possible to). We therefore prefer ``next'' in this case. ``Step'' would give us an error message about several missing source files; it would take a bunch of ``next''-clicks to get the green pointer back to our source code again.
#include<stdio.h>
int main() {
typedef struct person_struct {
/* Data elements */
char* name;
int age;
/* Link elements */
struct person_struct *next;
struct person_struct *prev;
} person_t;
person_t *start;
person_t *pers;
person_t *temp;
char *names[] = {"Linus Torvalds", "Alan Cox", "Rik van Riel"};
int ages[] = {30, 31, 32};
int count; /* Temporary counter */
start = (person_t*)malloc(sizeof(person_t));
start->name = names[0];
start->age = ages[0];
start->prev = NULL;
start->next = NULL;
pers = start;
for (count=1; count < 3; count++) {
temp = (person_t*)malloc(sizeof(person_t));
temp->name = names[count];
temp->age = ages[count];
pers->next = temp;
temp->prev = pers;
pers = temp;
}
temp->next = NULL;
printf("Data structure created\n");
return 0;
}
Although you might know the names used in the example, they are not important. The ages are chosen at random!
The code defines a double linked list of person-elements that stores two personal properties (name and age) together with two pointers (to the next and previous person in the list). Since this is one of the most important structures in C, every programmer should have seen something like this already several times before, normally in a more complete fashion. As before, our program does not perform a too important job: It just builds a data structure in memory and then exits, but this is sufficient for our purposes. As usual, the program must be compiled with debugging symbols included and then loaded into ddd.
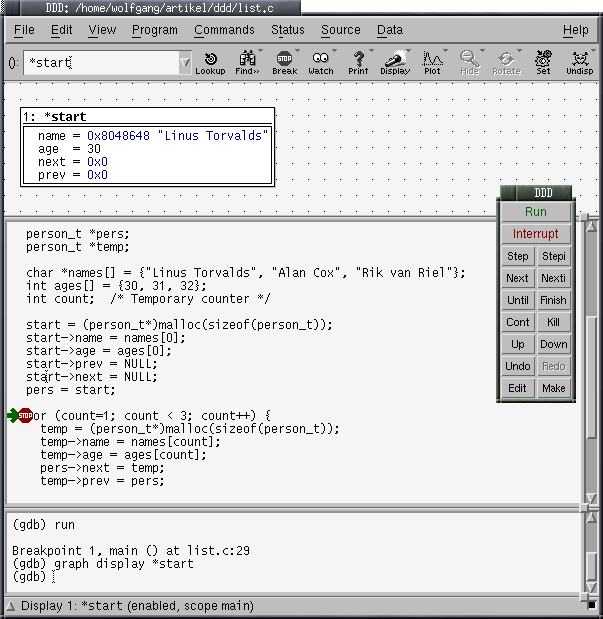
For this time, we set our first breakpoint in line 28 (the beginning of the for-loop) and start our program afterwards. Place the mouse pointer over the start-identifier: ddd will show you in the value tooltip appearing after a small amount of time that it is a pointer to an instance of struct person_t at a certain memory location given in hexadecimal notation. A perfect candidate for graphical visualisation!
Pop up the context menu by pressing the right mouse button over the start identifier and select "Display *start" - the star is needed so that ddd automatically dereferences the pointer and shows the structure's contents. A new section in the upper part of the ddd window will show up, containing a figure visualising start's contents: name and age are set to the values assigned a few lines before, and next, prev contain NULL pointers as expected. Figure 2 shows the box that you should see on your display (the char pointer's hexadecimal value may vary on your system, though).
This is already a pretty amazing feature, isn't it? But let's execute
our program a little further, seeing how our data structure is built up
in memory. Use the ``next''-button to step through the for loop's body
until line 34 (pers->next = temp) is reached: The second person's data
structure is built and connected with the first person by then.
When you watch the graph display afterwards, you can see that the
next-field of our first person has a value different than
0 now, meaning that it points to another structure: The clou: If you
double-click
on this value, a new box with the second person's structure opens, and
the pointer from person 1 to person 2 is automatically displayed as an
arrow between the boxes.
We take a different way to create the third person's data structure, because it is inconvenient to step through all single lines of a code just to see the result. Let's apply another breakpoint in line 39 which contains the printf(...)-statement. Pressing ``cont'' continues the program flow until another breakpoint (our fresh set one) is reached.
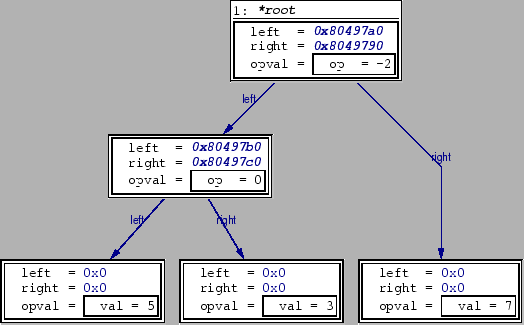
We can display the third person's data structure in the usual way. But now, we do not just want to see the pointers from person n person n+1, but also the backward pointers! Double click, for example, on the prev-field in the second graph: Another box pops up, duplicating the first person's box in the display! The same thing happens for the prev-pointer of the third person. This is obviously not what we want, because the same structure should not be displayed twice. We have to tell ddd to take care about this.
Ddd uses a feature called alias detection in order to achieve this,
which can be activated by activating the Data->Detect Aliases menu
entry. The display should look like figure 3 now.
All pointers are shown in the correct manner, giving us a quite good impression of the data structure in memory. Sadly, alias detection especially with tight connected structures has the drawback of slowing down ddd, since several memory locations must be compared after every program step in order to see which structures in the display represent the same memory location, compacting the graph respectively. Additionally, alias detection is only available with source languages that allow the back-end debugger to provide addresses of arbitrary objects, limiting the possible choices to C, C++ and Java at the moment.
#include<stdio.h>
/* Create a binary tree structure representing an arithmetic expression */
enum operator { plus, minus, times, div };
typedef struct tree_struct {
struct tree_struct *left;
struct tree_struct *right;
union {
int op:2;
int val;
} opval;
} tree_t;
int main() {
tree_t *node;
tree_t *root = (tree_t*)malloc(sizeof(tree_t));
root->opval.op = times;
node = (tree_t*)malloc(sizeof(tree_t));
node->right = NULL;
node->left = NULL;
node->opval.val = 7;
root->right = node;
node = (tree_t*)malloc(sizeof(tree_t));
node->opval.op = plus;
root->left = node;
node = (tree_t*)malloc(sizeof(tree_t));
node->left = NULL;
node->right = NULL;
node->opval.val = 5;
root->left->left = node;
node = (tree_t*)malloc(sizeof(tree_t));
node->left = NULL;
node->right = NULL;
node->opval.val = 3;
root->left->right = node;
printf("Tree created\n");
return 0;
}
The program creates a tree representing a arithmetic expression in the way compilers see them after the completion of the parsing process: Parentheses are superfluous in this form, since the graph structure contains this information intrinsically. Each node contains either an arithmetic operator (plus, minus, times or div, as defined by the enumeration operators) or a certain (integer) value. In explicit notation, the expression represented by the data structure is (5+3)*7
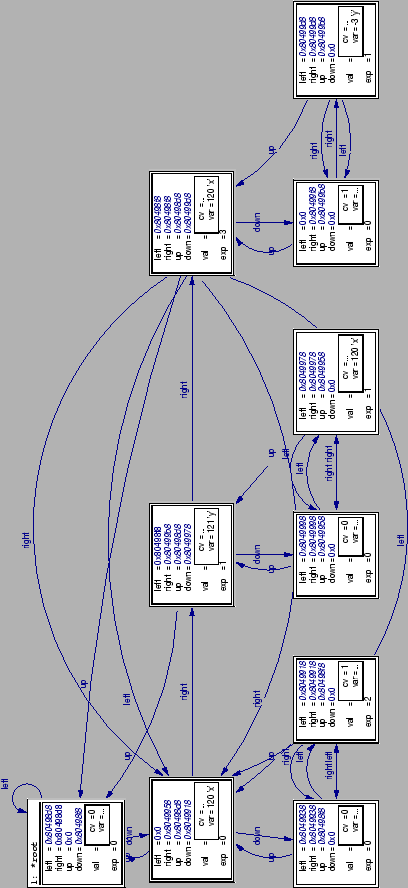
Run the program (after setting a breakpoint before the end, but after building the data structure), display the root element and open all subsequent members via double-clicking on the left/right-members of the structure. You can get all information about the memory structure, but it does not look very nice. We want to achieve a look like in figure 4:
One change compared to the picture produced by simply unfolding the
tree is obvious: All elements are layed out in a ordered manner. This can
certainly be achieved by using the mouse to drag the elements to their
respective locations, but is not very convenient: A much simpler method
(at least for the user) is the automatic layout capability provided by
ddd. To use it, we simply need to select the menu entry
Data->Layout Graph (or use the shortcut ALT+Y). ddd
layouts the graph in the manner shown afterwards.
Note that another manual change was applied to the graph. Since we use a union structure to represent either a value or an operator in every node, ddd displays both possibilities at a time. This may be somewhat confusing and should be avoided. The rules are clear: If both left and right pointer are set to NULL, the node represents a number, otherwise an operator. Select ``Undisplay'' from the context menu accessible with the right mouse button to delete the unwanted entry. Ddd will ask if the action should be applied to all fitting structures or just the present one; since we want to delete different values from different boxes, the second alternative must be selected.
Ddd offers some additional features dealing with graph layout in the data menu. The reader will surely figure out how to use them very quickly since they are quite intuitive and self-explaining.
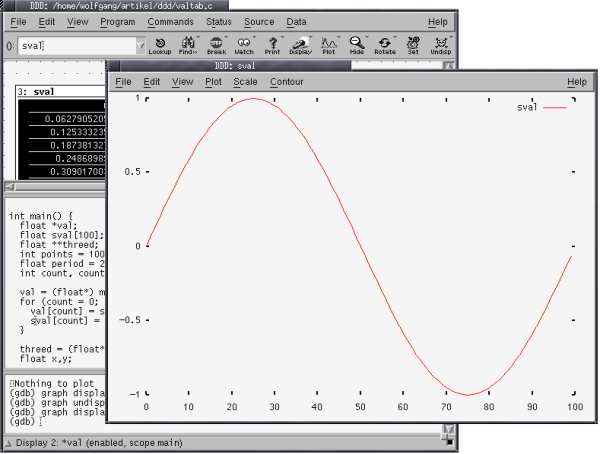
Program valtab.c shows a program that creates a value table for a certain function (in this case, a two dimensional sine function). Note that you must compile this program using the -lm switch in gcc in order to include the mathematical library!
#include<stdio.h>
#include<math.h>
int main() {
float *val;
float sval[100];
float **threed;
int points = 100;
float period = 2*M_PI;
int count, count2;
val = (float*) malloc(points*sizeof(float));
for (count = 0; count < points; count++) {
val[count] = sin(count * period/(float)points);
sval[count] = val[count];
}
threed = (float**)malloc(points*sizeof(float));
float x,y;
for (count = 0; count < points; count++) {
threed[count] = (float*)malloc(points*sizeof(float));
for (count2 = 0; count2 < points; count2++) {
x = count*period/(float)points;
y = count2*period/(float)points;
threed[count][count2] = 1.0f/(x+y)*sin(x+y);
}
}
/* Normally, we would write the generated data into a file or so. */
printf("Value tables created\n");
return 0;
}
Normally, most programs will deal with more complicated functions (or acquire their data sets in a different way), but the basic principle (filling some values into an array) remains unchanged in all cases.
We use three kinds of arrays in our sample program to demonstrate the
different methods for plotting data. The simplest possibility is
a static, one-dimensional array, as is sval. In this case,
we only need to highlight the identifier by clicking on it with the
right mouse button and pressing on the ``plot'' icon found in the upper zone
of the window - voila, a new gnuplot-window with the desired graph opens.
The graph's appearance can be customised with several menu entries;
figure 6 shows the output with the plot style changed to
``lines'' from the default value ``points'' by selecting Plot->Lines
in the menu.
The situation is somewhat more complicated with dynamical created arrays, since ddd cannot determine their lengths automatically. A workaround for this is the use of so-called array slices that must be defined manually in the debugger interaction part in the lower part of the ddd window.
The expression graph display val[0]@points creates such an array
slice, where the index-expression [0] denotes the lower and
@points denotes the upper bound for the used values (instead
of the memory value points, a simple integer number can
be used likewise). Plotting this graph is achieved in the same way as before
(by pressing the ``plot''-button) and gives (surprise, surprise) the same
result, since identical datasets are used.
Plotting three-dimensional graphs works pretty much the same way: The
identifier of static array needs just to be highlighted with the mouse
in order to apply the ``plot''-button afterwards, while an array slice has
to be created when dynamic allocated structures are used. The syntax for this
is graph display threed[0][0]@points@points, as the reader
will have expected.
Since the customisation features available with gnuplot for three-dimensional graphs are not very well supported in the ddd-interface, such plotting attempts will normally tend to give not very good and meaningful results as with two-dimensional plots.
File->Print Graph. A menu pops up
offering some choices, and hitting the print button produces
either a file or sends the output directly to the printer.
The same approach may be applied for plots; the only difference is that fewer options are available in the print dialog. While graphs can be exported to Postscript as like as well as to the fig-format format (as used by the classical Unix drawing tool xfig), plot printing can be exported only to Postscript.
Ddd offers many more features such as watchpoints, multiple language support etc. These are beyond the topic of this article, since we do not intend to repeat the excellent documentation coming with ddd. (The documentation is available from http://www.gnu.org/software/ddd.) Instead, we encourage readers to explore ddd's rich set of features themselves, debugging their own programs.
As a last remark, let's consider a quotation that ddd uses as one of its "tips of the day", because it expresses the importance (and limits) of debugging very well:
The debugger isn't a substitute for good thinking. But, in some cases, thinking isn't a substitute for a good debugger either. The most effective combination is good thinking and good debugger. --Steve McConnell, Code Complete
 Wolfgang Mauerer
Wolfgang Mauerer